The enterprise-grade desktop SEO crawler for Windows, macOS and Linux — the spider in-house SEO teams at SaaS platforms, marketplaces and large e-commerce brands run nightly against millions of URLs.
The Screaming Frog SEO Spider is a desktop SEO crawler that lets enterprise teams keep technical hygiene under control across large, fast-changing properties — without shipping crawl data to a vendor cloud.
Evaluate it free on 500 URLs with no sign-up and no expiry, then unlock unlimited crawls under a shared team licence. Flags 300+ SEO issues across technical, on-page, performance and content layers.
v21.0AI API Integration · Accessibility · Email Notifications
v20.0Custom JS Snippets · Mobile Usability · Carbon Footprint
v19.0UI Refresh · Segments · 3D Visualizations
What can your team do with the SEO Spider?
Surface 300+ SEO issues, warnings and opportunities across every property in your portfolio — and feed the results straight into your reporting stack.
Find Broken Links
Sweep a domain for 404s and 5xx errors, then bulk-export source URLs into the engineering queue.
Audit Redirects
Map 301s and 302s, untangle chains and loops, and upload legacy URL lists to validate every hop before a migration goes live.
Analyse Page Titles & Meta Data
Catch titles and descriptions that run long, fall short, go missing or repeat across thousands of templated URLs.
Discover Duplicate Content
Detect exact duplicates by MD5 hash, near-duplicate titles and headings, and the thin pages faceted navigation spawns.
Extract Data with XPath
Scrape any element with CSS Path, XPath or regex — price tiers, SKUs, inventory and structured data — into named columns for BI.
Review Robots & Directives
Audit URLs gated by robots.txt, meta robots or X-Robots-Tag, then verify canonicals and hreflang across multi-region storefronts.
Generate XML Sitemaps
Build XML and Image XML Sitemaps from a clean crawl, with full control over which URLs ship plus last-modified, priority and change-frequency.
Integrate with GA, GSC & PSI
Wire in GA4, Search Console and PageSpeed Insights APIs so traffic, impressions and Core Web Vitals land beside every URL.
Crawl JavaScript Websites
Execute pages through the embedded Chromium rendering service to crawl component-driven storefronts on React, Angular, Vue or Next.js.
Visualise Site Architecture
Inspect internal linking and crawl depth on sprawling catalogues via force-directed diagrams, tree graphs and 3D site maps.
Schedule Audits
Queue unattended nightly or weekly crawls with auto-export to Google Sheets, or trigger them from the command line.
Compare Crawls & Staging
Track how issue counts trend release over release and diff staging against production with advanced URL Mapping.
300+ checks across every layer of an enterprise site
Technical
Broken links & 404 errors
Redirect chains & loops
Blocked resources (robots.txt)
HTTPS / mixed content
Hreflang & internationalisation
Pagination (rel=next/prev)
On-Page SEO
Page titles & meta descriptions
H1, H2 and heading structure
Canonical tags & noindex
Duplicate & near-duplicate content
Thin / low-content pages
Structured data & schema.org
Performance & UX
Core Web Vitals (PSI/Lighthouse)
Mobile usability auditing
Carbon footprint & rating
AMP validation
Accessibility auditing
Image optimisation & alt text
Analysis & AI
Internal linking & anchor text
N-grams content analysis
Semantic similarity analysis
Content cluster visualisation
Crawl comparison & tracking
AI content generation (OpenAI/Gemini)
What enterprise SEO leaders say
★★★★★
"We run scheduled overnight crawls of a 3-million-SKU catalogue and the regression report is waiting before standup. Nothing else lets an in-house team monitor a property this large without a cloud contract or per-URL bill."
★★★★★
"Custom extraction pulls our price tiers and inventory into named columns and the CSV drops straight into Snowflake. It has quietly become the data source half our SEO dashboards depend on."
★★★★★
"Team licences let eight consultants share identical crawl configs across rotating engagements, and procurement signed off in one cycle because the data never leaves the operator's machine — decisive for our regulated accounts."
★★★★★
"On migrations spanning hundreds of thousands of URLs, the redirect mapping and staging-vs-production diff keep us out of trouble. It is the first tool we install on every new analyst's workstation."
// Enterprise playbook · 2026
The enterprise case for Screaming Frog at SaaS & e-commerce scale
When a SaaS catalogue hits 500k URLs or a marketplace passes two million products, browser-tab crawlers stop working. Screaming Frog is the desktop spider that in-house SEO teams at enterprise retailers, B2B SaaS vendors and regulated publishers run nightly to keep technical hygiene under control without shipping a customer record to a third-party cloud.
This page lays out that playbook: how the screaming frog seo spider chews through million-URL crawls on one workstation, how a team licence is shared across consultants, how scheduled audits stream into BI dashboards via CSV export, and how to use screaming frog to improve on page seo where spreadsheets long since gave up.
Enterprise snapshot: screaming frog free covers 500 URLs for QA pods; the £199/yr Pro licence covers two machines per consultant and adds unlimited URLs, scheduled monitoring and CSV pipelines into Looker, Tableau or Snowflake.
Why it fits the enterprise stack
What is Screaming Frog for an in-house team at scale
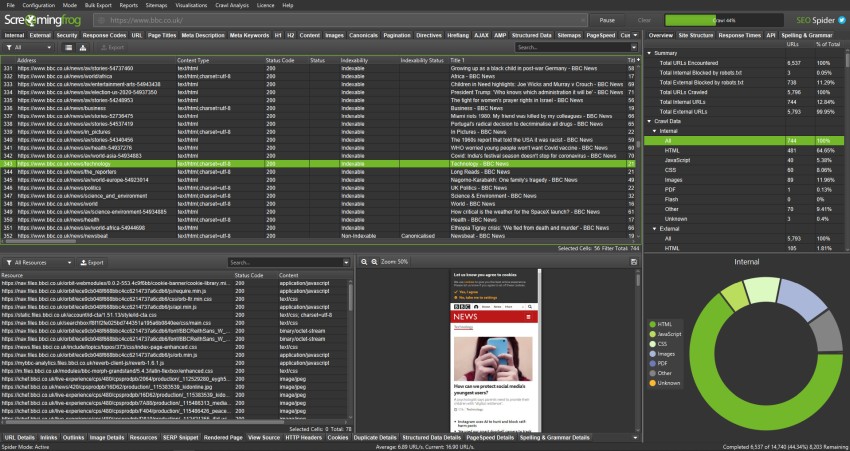
What is screaming frog at enterprise scale: a desktop spider that crawls Shopify Plus-sized catalogues on one workstation, renders JavaScript with an embedded Chromium engine and writes the crawl into a local database that ingests into BigQuery, Snowflake or Power BI. Because the screaming frog seo tool runs on the operator's laptop, no PII or order data transits a vendor cloud — the case that lands it in finance, healthcare and government.
Enterprise seo screaming frog audits cover 300+ issue types across titles, meta descriptions, headings, canonicals, hreflang, structured data, internal links, redirect chains, response codes and DOM weight. One licence replaces a sitemap generator, broken-link checker, redirect mapper, schema validator and log-file companion — each otherwise its own procurement cycle.
300+SEO issues reported
v24.0May 2026
500 URLsFree tier
3 OSMac/Win/Linux
Version 24 · May 2026
The v24 capabilities that changed the enterprise workflow
Three v24 additions reshape how a 12-person SEO programme runs — the screaming frog seo spider features that justify the upgrade at million-URL scale.
MCP orchestration from Claude
Hand the spider to an AI agent: a PM asks Claude to "audit the new checkout flow against last week's baseline" and the screaming frog seo spider runs the crawl, diff and export — no GUI.
Nightly scheduled monitoring
Auto Compare crawls run unattended overnight, diff the prior run and email a regression report at 06:00 — redirect-chain and 404 alerts reach release managers before standup, zero analyst keyboard time.
Uncrawlable link detection
SPA frameworks hide navigation behind event handlers; the new report flags JS-injected URLs the spider cannot reach, exposing dead zones in large React storefronts.
The enterprise feature backbone sits underneath v24: JavaScript rendering via a built-in Chromium WRS for React, Angular, Vue and Next.js storefronts; custom extraction with XPath, CSS Path and regex to pull SKUs, price tiers and inventory counts into named columns; and a full GA4, Search Console and PageSpeed Insights API overlay joining traffic, CTR and Core Web Vitals to every URL.
A built-in structured-data validator handles schema.org and Google rich-result checks, and the companion log-file analyser shows how Googlebot spends crawl budget across faceted-navigation parameters — the biggest indexation problem at scale.
Team licensing
Screaming Frog pricing for in-house teams
Screaming frog pricing scales linearly per consultant — the reason it survives finance review at large organisations. Each Pro seat covers two installs, so a senior SEO runs identical configs on a laptop and a workstation without paying twice.
Free forever
£0/yr · no sign-up
Screaming Frog Free
Up to 500 URLs — ideal for QA pods spot-checking new templates
All core SEO reports for proof-of-concept rollouts
XML sitemap generator for staging environments
Response codes & canonical analysis on release branches
Mac, Windows and Linux runtime parity
No trial countdown — usable on any developer laptop
Pro licence
£199/yr · ~$250 USD
Pro & Team licences
Unlimited URLs — proven at 2M URLs on 32 GB workstations
JavaScript rendering for headless storefronts
Custom extraction (XPath, regex) for SKU/price/inventory columns
GA4, Search Console, PageSpeed and Ahrefs APIs
Scheduled crawls, Auto Compare and CSV export for BI pipelines
One seat covers two machines per consultant
Cross-platform
Screaming Frog on Mac vs Windows
Native builds for Mac, Windows and Linux mean a mixed-hardware team gets identical reports whoever is at the keyboard. The only practical differences are install paths and how much memory you hand the crawler — which matters once a crawl tops a million URLs.
Screaming Frog on MacUniversal binary · M1 → Tahoe
Shipped as a notarised universal binary across macOS Monterey (12) through Sequoia (15) and Tahoe (26). The Apple Silicon advantage is real — an M3 Pro finishes a 100k-URL rendered crawl in roughly half the time of a comparable Intel Core i9, which compounds across enterprise catalogues.
Lift the default 2 GB heap under Configuration → System → Memory before pointing it at production. Binaries live at /Applications/Screaming Frog SEO Spider.app, the database under ~/Library/Application Support/Screaming Frog SEO Spider/.
Screaming Frog on Windows64-bit Win 10 & Win 11
On 64-bit Windows 10 and 11 the same Configuration → System → Memory dialog governs throughput. A 32 GB workstation can hand 16 GB or more to the heap — that headroom is what makes multi-million-URL database-mode crawls viable on a desktop, not a server cluster.
Files install to C:\Program Files (x86)\Screaming Frog SEO Spider\ with the database under %APPDATA%\Screaming Frog SEO Spider\. No feature is platform-locked — every report, API integration and scheduled job behaves identically on Windows and Mac.
vs the alternatives
Screaming Frog vs Ahrefs, SEMrush, SE Ranking, DeepCrawl
Procurement teams weigh up screaming frog vs ahrefs, ahrefs vs screaming frog and screaming frog vs semrush — yet these tools rarely overlap. Most enterprise stacks budget for a desktop crawler and a cloud research suite together; each owns a job the other was never built for.
vs Ahrefs
Is ahrefs like screaming frog? Not really.Ahrefs is a hosted suite anchored on its backlink index, keyword corpus and rank tracker. Its Site Audit is the nearest equivalent, yet it runs on Ahrefs infrastructure and meters audits against a URL quota. The screaming frog seo spider does no keyword research — it is a crawler, but one that runs locally and never bills per URL.
vs SEMrush
Overlap is limited to the audit moduleScreaming frog vs semrush comes down to one shared surface: the SEMrush Site Audit. Everything else SEMrush sells — keyword research, competitive intelligence, PPC tooling — sits outside what a desktop crawler does, so large teams run both rather than choose.
vs SE Ranking
Budget cloud suite, not a desktop crawlerSe ranking vs screaming frog pits a cheaper hosted Ahrefs/Semrush rival against the crawl-only seo screaming frog. SE Ranking bundles a Site Audit too, but the same constraint applies — metered cloud crawling versus unlimited local crawls bounded only by RAM.
vs DeepCrawl
The genuine enterprise head-to-headScreaming frog vs deepcrawl (now Lumar) is the comparison that matters for large organisations. DeepCrawl is a cloud crawler with unlimited URLs, hosted scheduling and shared workspaces. The screaming frog alternative case favours DeepCrawl when you continuously monitor well past 1M URLs; under that ceiling the desktop tool is faster to spin up and far cheaper per crawl.
Five-pass audit workflow
How to use Screaming Frog to improve on page SEO
At enterprise scale, how to use screaming frog to improve on page seo is less a one-off audit than a repeatable five-pass routine you codify once and then schedule to run on its own.
Render the full production crawl
Switch on Configuration → Spider → Rendering → JavaScript and use database storage mode so a million-URL property fits on disk. Rendering exposes content a raw HTML pass misses.
Prioritise by business impact, not issue count
From Reports → Crawl Overview, segment by template or revenue line. A duplicate title on 40k category pages outranks a missing H1 on one legal page — fix in the CMS, then re-crawl staging.
Layer in Search Console & GA4
Authorise the integrations under Configuration → API Access so impressions, CTR and sessions sit beside each URL — the overlay you use to defend remediation spend to stakeholders.
Ship a clean XML sitemap
Use Sitemaps → XML Sitemap to generate from the validated crawl, drop redirected and 404 URLs, then push to Search Console as part of the release checklist.
Hand the recurring crawl to the scheduler
Register a nightly or weekly job with Auto Compare on; the regression diff lands in the team inbox automatically. Identical behaviour across all three OSes lets any operator own the rota.
Codify this once and a sprawling property polices itself between releases. Grab the latest build below.
Screaming Frog
Crawl 500 URLs free, then scale to your whole estate
The desktop SEO crawler enterprise teams standardise on. No sign-up to evaluate; shared licences when you scale. Windows, macOS, Linux.
Yes — free to download, no sign-up or expiry, with the full core audit suite on the 500-URL free tier. It is the no-cost way for an enterprise team to run a proof-of-concept before buying shared licences for unlimited crawling.
The free tier covers 500 URLs per session — enough for a QA pod to spot-check a new template or validate a single site section. A paid licence lifts the cap entirely; teams routinely run crawls into the millions of URLs on a well-provisioned workstation.
It runs natively on Windows, macOS and Linux, with native Arm64 Linux added in version 24 — handy for teams that automate crawls on Arm-based cloud instances. The 64-bit build is a single download that behaves identically across all three platforms.
Released 19 May 2026, version 24.0 shipped MCP (Model Context Protocol) so AI agents can drive crawls, Auto Compare between scheduled runs, crawl-delta email alerts with export attachments, uncrawlable link detection, a usage-statistics dashboard and native Arm64 Linux builds — squarely aimed at automated, team-scale workflows.
Yes — an embedded Chromium Web Rendering Service executes pages so the crawler reaches content on React, Angular, Vue, Next.js and other component-driven storefronts. Rendering is a per-crawl toggle, so teams can run fast raw-HTML passes for monitoring and full renders for deep audits.
Yes — native connectors for Google Analytics 4, Search Console and PageSpeed Insights join traffic, impressions, CTR and Core Web Vitals to each URL, and the merged dataset exports to CSV for ingestion into Looker, Tableau, Power BI or a warehouse.